ViSudoku
Takes an image of a sudoku puzzle as input and solves it. Uses OpenCV and scikit-learn.
Overview
Here is a basic outline of how this algorithm works
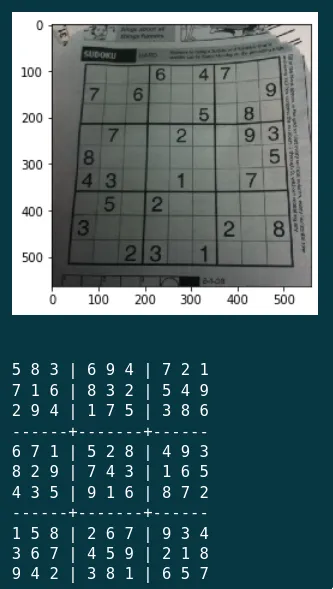
- Once I get the image, the largest 'box' is assumed to be the sudoku puzzle.
- The box is then extracted from the image and 'flattened'.
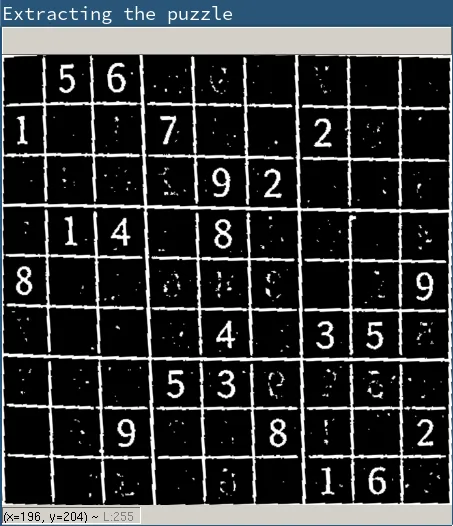
- Now that we have the puzzle, we need to get the individual digits. For this, I 'reinforce' the grid by drawing more lines above it. I also add the bounding box seperately. This was done to 'strongly' divide to seperate out the individual digits.
- The next step is to extract all the 'boxes' in the image. The largest 82 are picked. The largest one is the whole box and the next 81 are the individual boxes.
- Now that we have each digit, it is necessary to have them in the correct order to reconstruct the puzzle. For this, I use the central coordinates to arrange them back in place.
- Now, I use a knn classifier to recognize each digit (with near perfect accuracy)
- The only thing left is to solve this puzzle, which can be done by recursion.
- It has been packaged as a docker image with a UI
- The solution is cached so, if the same image is given, it runs much faster
· · ·
Image(s)





· · ·
Demo
· · ·
Code
This code, along with the printed digit training data can be found on github, at yoogottamk/visudoku.